
AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Shane (Seungwhan) Moon Is a Research Scientist at Meta Reality Labs.
He and the Meta team have just released their most recent work – AnyMAL — a unified Multimodal LLM built on Llama-2 that can reason over various inputs, e.g. images, audio, motion sensors.
Check out their research paper for more information on the model training, evaluation, safety and more! (https://lnkd.in/ggabfced)
Title: AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Authors: Seungwhan Moon, Andrea Madotto, Zhaojiang Lin, Tushar Nagarajan, Matt Smith, Shashank Jain, Chun-Fu Yeh, Prakash Murugesan, Peyman Heidari, Yue Liu, Kavya Srinet, Babak Damavandi, Anuj Kumar
Affiliation: Meta & Meta Reality Labs
Summary: We present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module. To further strengthen the multimodal LLM’s capabilities, we fine-tune the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. We conduct comprehensive empirical analysis comprising both human and automatic evaluations, and demonstrate state-of-the-art performance on various multimodal tasks.
AnyMAL Overview
The paper introduces the Any-Modality Augmented Language Model (AnyMAL). This model can reason over various input modalities like text, image, video, audio, and IMU motion sensor, producing textual responses. It builds upon the capabilities of state-of-the-art Large Language Models (LLMs) and uses a pre-trained aligner module to convert modality-specific signals to a joint textual space. The model has been fine-tuned with a multimodal instruction set to cover diverse topics beyond simple Q&A. Comprehensive evaluations show state-of-the-art performance on various multimodal tasks.
Methodology
The underlying methodology that powers AnyMAL is groundbreaking, especially when considering its vast range of potential uses. The team of researchers harnessed the power of open-source tools and scalable strategies to train this advanced multimodal language model.
A pivotal innovation in this process is the introduction of the Multimodal Instruction Tuning dataset (MM-IT). This dataset is not just any collection; it is a carefully crafted compilation of annotations tailored for multimodal instructional data. The MM-IT dataset was instrumental in the training phase of AnyMAL, equipping it with the capability to comprehend and react to instructions that merge multiple sensory data points.
What truly sets AnyMAL apart is its adeptness at seamlessly integrating multiple modalities. Its proficiency is evident across a spectrum of tasks, and this becomes even more pronounced when juxtaposed against other vision-language models.
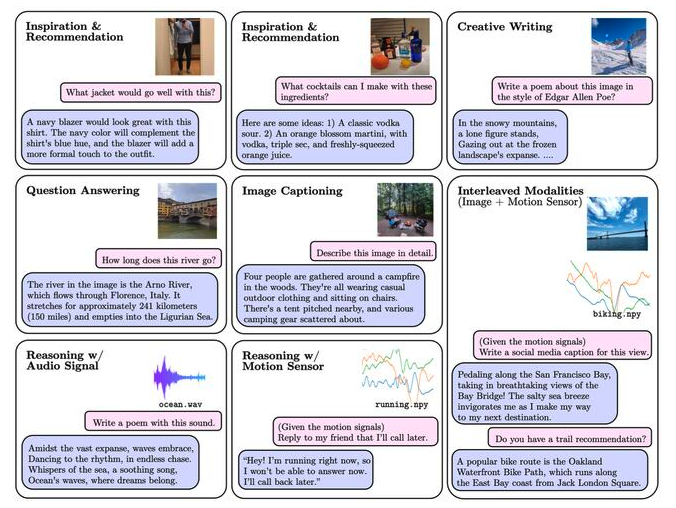
AnyMAL Examples:
Through different demonstrations, the prowess of AnyMAL becomes undeniably evident.

In this creative writing example, AnyMAL responds to the prompt, “Write a joke about it,” with a funny response related to the image of a Lego nutcracker doll. This showcases its visual recognition skills and its capacity for creativity and humor.

In this recommendation query, regarding wine pairing with steak, AnyMAL accurately identifies the wine that pairs better with steak based on the image of two wine bottles. This demonstrates its ability to provide practical recommendations grounded in a visual context.

In this question-and-answering scenario, AnyMAL correctly identifies the Arno River in an image of Florence, Italy, and provides information about its length. This highlights its strong object recognition and factual knowledge capabilities.
Summary:
AnyMAL marks a major advancement in understanding language across multiple modes. It tackles a core challenge in AI, allowing machines to understand and produce language while integrating a range of sensory data. Built on an extensive multimodal dataset and robust training, AnyMAL excels in numerous activities, ranging from imaginative writing to actionable suggestions and information extraction.