
Monthly Archives: October 2023

That Stinks! New GenAI Multimodal type: Smell to Text
The September 1 issue of Science has a great article highlighting a groundbreaking AI program, specifically a graph neural network, that excels at emulating human olfactory abilities, especially with basic scents. The study results, reported show that the program, a so-called graph neural network, is excellent at imitating human sniffers, at least when it comes to simple odors….

Harnessing Language Models in Enterprises
In today’s digital age, language models, especially Large Language Models (LLMs), have become a cornerstone for many enterprise applications. From chatbots to content generation, their versatility is unmatched. However, as enterprises seek to integrate these models into their workflows, they often grapple with questions about creation, fine-tuning, usage and security and safety. This article delves…

The Creator Economy and Generative AI
On October 4, 2023 the Federal Trade Commission hosted a virtual roundtable to discuss the impact of generative artificial intelligence on creative fields. The Federal Trade Commission is seeking to better understand how these tools may impact open and fair competition or enable unlawful business practices across markets, including in creative industries. Discussion Video: This…

AI and Empathy: The Future of Human-Machine Interactions
I recently saw this job post for an Empathy Annotator: https://www.linkedin.com/jobs/view/3726958446 “You will learn to systematically identify elements that embody an empathic response using an evidence-based qualitative labeling system. In short, you will contribute to the core technology of our product – defining empathy. This will involve: – Attend training online to learn what makes…

VIDEODIRECTORGPT: A Leap Forward in Multi-Scene Video Generation from Text
Generating video content automatically from text descriptions has been a longstanding challenge in the realm of artificial intelligence. While there have been significant advancements in producing short video clips from text prompts, the creation of detailed, multi-scene videos with smooth transitions remains a formidable task for AI systems. In a new paper (Github page here) titled “VIDEO DIRECTOR…

Where We Go From Here with OpenAI’s Mira Murati
As part of the a16z Revolution Series, Mira Murati CTO of OpenAI talks to Andreesen Horowitz’s Martin Casado about where OpenAI is going in the next few years. Martin Casado:I would love for you to prognosticate a little bit on where you think this is all going like three years or five years or ten years. Mira…
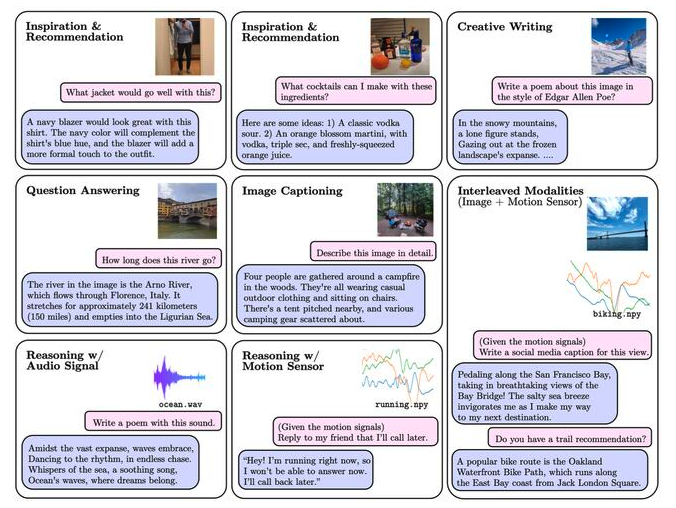
AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Shane (Seungwhan) Moon Is a Research Scientist at Meta Reality Labs. He and the Meta team have just released their most recent work – AnyMAL — a unified Multimodal LLM built on Llama-2 that can reason over various inputs, e.g. images, audio, motion sensors. Check out their research paper for more information on the model training,…

ChatGPT is Only the Beginning
With the announcement in September that ChatGPT has become Multimodal (or Multi-Modal) – (ChatGPT Can Now See, Hear and Speak) ChatGPT will now support both voice prompts from users and their image uploads. These new capabilities will offer a new, more intuitive type of interface by allowing you to have a voice conversation, or show…
AI Food Fights in the Enterprise with Databricks’ Ali Ghodsi
Excellent discussion with Ali Ghodsi, CEO and cofounder of Databricks, and Ben Horowitz, cofounder of Andreessen Horowitz a16z. This conversation was part of the a16z AI Revolution series. Their discussion covers the data wars happening inside and outside of corporate enterprises and how they could impact the evolution of Large Language Models – LLMs. Key takeaways: Challenges for Enterprises Adopting…